Group-NMF with \(\beta\) -divergence¶
In [1] we propose an approach to speaker identification that relies on group-nonnegative matrix factorisation (NMF) and that is inspired by the I-vector training procedure. Given data measured with several subjects, the key idea in group-NMF is to track inter-subject and intra-subject variations by constraining a set of common bases across subjects in the decomposition dictionaries. This has originally been applied to the analysis of electroencephalograms [2]. The approach presented here extends this idea and proposes to capture inter-class and inter-session variabilities by constraining a set of class-dependent bases across sessions and a set of session-dependent bases across classes. This approach is inspired by the joint factor analysis applied to the speaker identification problem [3]. In the following, first the general NMF framework with \(\beta\) -divergence and multiplicative updates is describe, then we present the group-NMF approach with class and session similarity constraints.
NMF with \(\beta\) -divergence and multiplicative updates¶
Consider the (nonnegative) matrix \(\textbf{V}\in\mathbb{R}_+^{F\times N}\). The goal of NMF [4] is to find a factorisation for \(\textbf{V}\) of the form:
where \(\textbf{W}\in\mathbb{R}_+^{F\times K}\) , \(\textbf{H}\in\mathbb{R}_+^{K\times N}\) and \(K\) is the number of components in the decomposition. The NMF model estimation is usually considered as solving the following optimisation problem:
Where \(D\) is a separable divergence such as:
with \([.]_{fn}\) is the element on column \(n\) and line \(f\) of a matrix and \(d\) is a scalar cost function. A common choice for the cost function is the \(\beta\) -divergence [5] [6] [7] defined as follows:
Popular cost functions such as the Euclidean distance, the generalised KL divergence [8] and the IS divergence [9] and all particular cases of the \(\beta$-divergence\) (obtained for \(\beta=2\) , \(1\) and \(0\), respectively). The use of the \(\beta\) -divergence for NMF has been studied extensively in Févotte et al. [10]. In most cases NMF problem is solved using a two-block coordinate descent approach. Each of the factors \(\textbf{W}\) and \(\textbf{H}\) is optimised alternatively. The sub-problem in one factor can then be considered as a nonnegative least square problem (NNLS) [11]. The approach implemented here to solve these NNLS problems relies on the multiplicative update rules introduced in Lee et al. [4] for the Euclidean distance and later generalised to the the \(\beta\) -divergence [10] :
where \(\odot\) is the element-wise product (Hadamard product) and division and power are element-wise. The matrices \(\textbf{H}\) and \(\textbf{W}\) are then updated according to an alternating update scheme.
Group NMF with class and session similarity constraints¶
In the approach presented above, the matrix factorisation is totally unsupervised and does not account for class variability or session variability. The approach introduced in Serizel et al. [1] intends to take these variabilities into account. It derives from group-NMF [2] and is inspired by exemplar-based approaches for the speaker identification problem [12].
NMF on speaker utterances for speaker identification¶
In order to better model speaker identity, we now consider the portion of \(\textbf{V}\) recorded in a session \(s\) in which only the speaker \(c\) is active. This is denoted by \(\textbf{V}^{(cs)}\), its length is \(N^{(cs)}\) and it can be decomposed according to (1):
under nonnegative constraints.
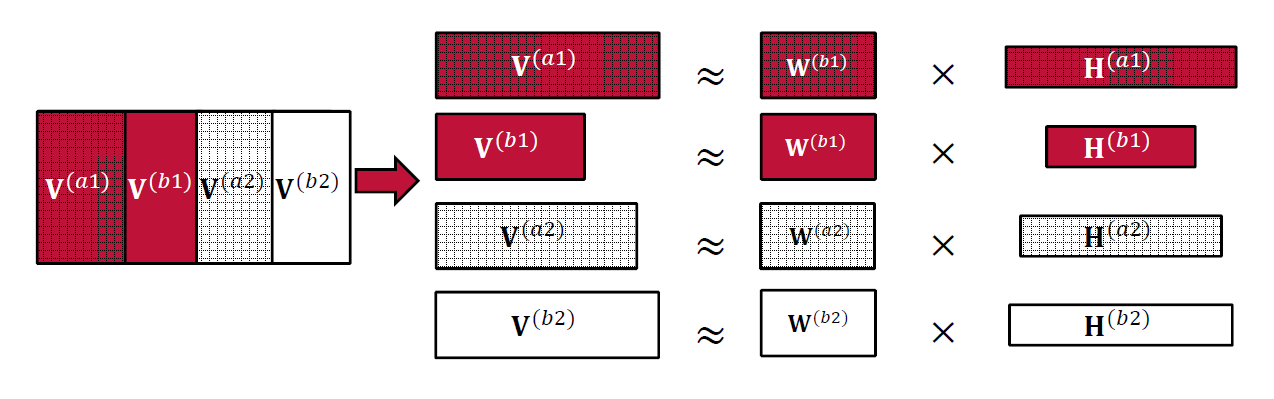
Fig. 1 NMF on speaker utterances
We define a global cost function which is the sum of all local divergences:
Each \(\textbf{V}^{(cs)}\) can be decomposed independently with standard multiplicative rules ((2), (3)). The bases learnt on the training set are then concatenated to form a global basis. The latter basis is then used to produce features on test sets.
Class and session similarity constraints¶
In order to take the session and speaker variabilities into account we propose to further decompose the dictionaries \(\textbf{W}\) similarly as what was proposed by Lee et al. [4]. The matrix \(\textbf{W}^{(cs)}\) can indeed be arbitrarily decomposed as follows:
with \(K_{\mathrm{SPK}} + K_{\mathrm{SES}} + K_{\mathrm{RES}} = K\) and where \(K_{\mathrm{SPK}}\), \(K_{\mathrm{SES}}\) and \(K_{\mathrm{RES}}\) are the number of components in the speaker-dependent bases, the session-dependent bases and the residual bases, respectively.
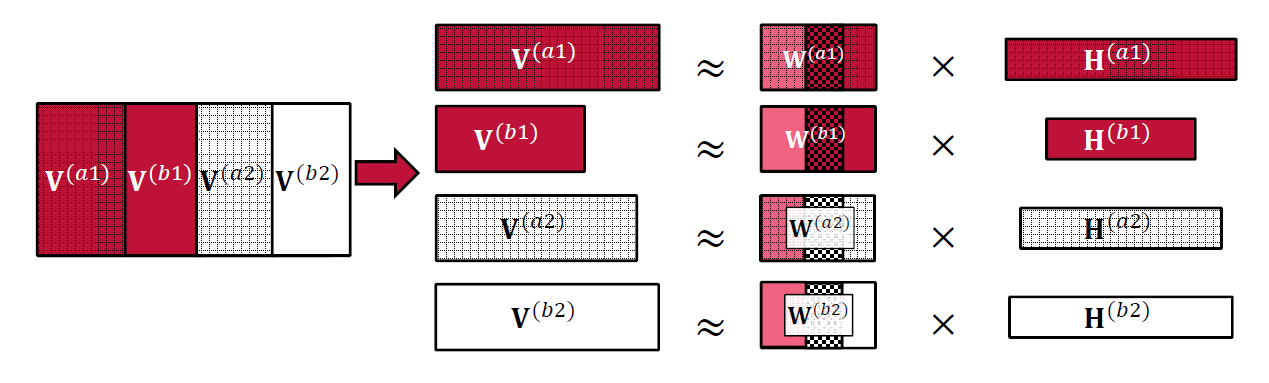
Fig. 2 Basis decomposition into \(\textbf{W}^{(cs)}_{\mathrm{SPK}}\), \(\textbf{W}^{(cs)}_{\mathrm{SES}}\) and \(\textbf{W}^{(cs)}_{\mathrm{RES}}\)
The first target is to capture speaker variability. This is related to finding vectors for the speaker bases (\(\textbf{W}^{(cs)}_{\mathrm{SPK}}\)) for each speaker \(c\) that are as close as possible across all the sessions in which the speaker is present, leading to the constraint:
with \(\|.\|^2\) the Euclidean distance and \(\alpha_1\) is the similarity constraint on speaker-dependent bases.
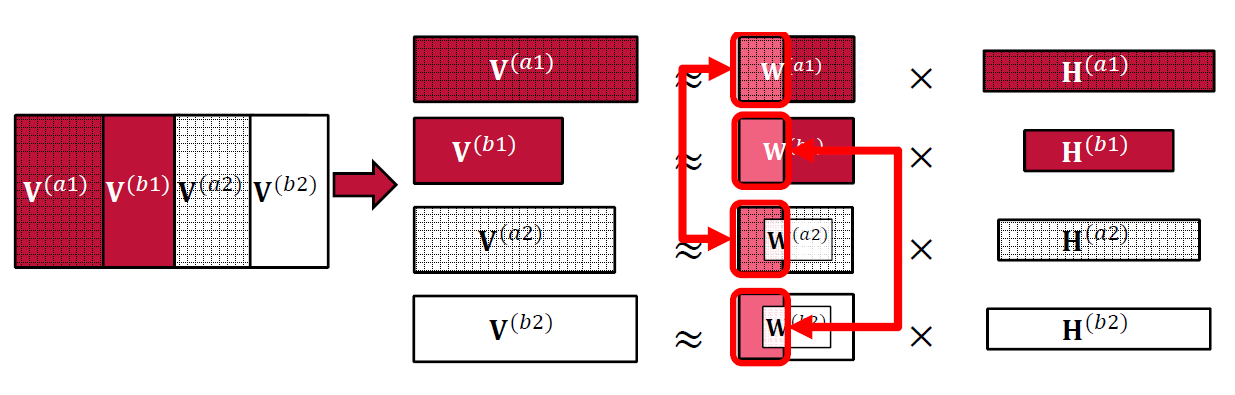
Fig. 3 Speaker similarity constraint
The second target is to capture session variability. This can be accounted for by finding vectors for the sessions bases (\(\textbf{W}^{(cs)}_{\mathrm{SES}}\)) for each session \(s\) that are as close as possible across all the speakers that speak in the session, leading to the constraint:
where \(\alpha_2\) is the similarity constraint on session-dependent bases.
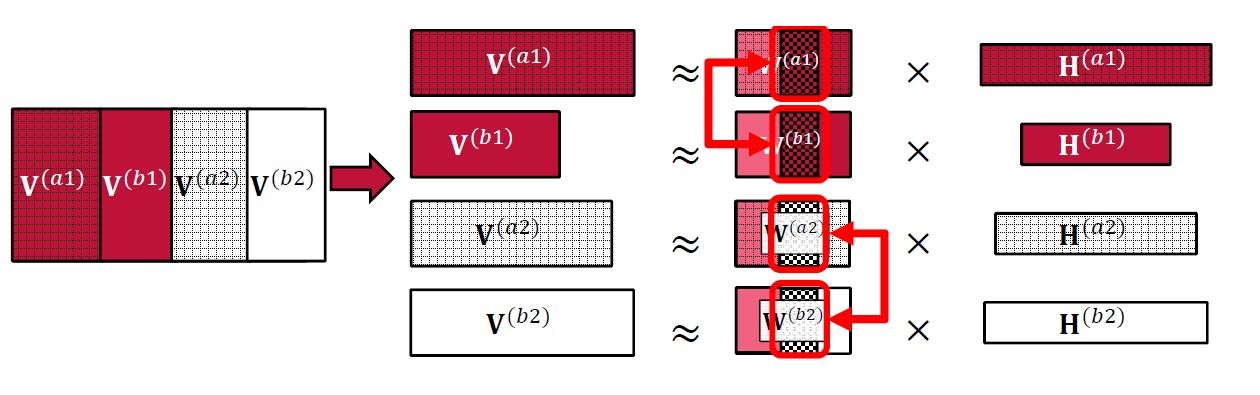
Fig. 3 Session similarity constraint
The vectors composing the residual bases \(\textbf{W}^{(cs)}_{\mathrm{RES}}\) are left unconstrained to represent characteristics that depend neither on the speaker nor on the session.
Minimizing the global divergence (4) subject to constraints (5) and (6) is equivalent to the following problem:
which in turn leads to the multiplicative update rules for the dictionaries \(\textbf{W}^{(cs)}_{\mathrm{SPK}}\) and \(\textbf{W}^{(cs)}_{\mathrm{SES}}\):
We obtained these update rules using the well know heuristic which consists in expressing the gradient of the cost function (7) as the difference between a positive contribution and a negative contribution. The multiplicative update then has the form of a quotient of the negative contribution by the positive contribution. The update rules for \(\textbf{W}^{(cs)}_{\mathrm{RES}}\) are similar to the standard rules:
Note that the update rules for the activations (\(\textbf{H}^{(cs)}\)) are left unchanged.
Download¶
Source code available at https://github.com/rserizel/groupNMF
Citation¶
If you are using this source code please consider citing the following paper:
Reference
- Serizel, S. Essid, and G. Richard (2016, March). “Group nonnegative matrix factorisation with speaker and session variability compensation for speaker identification”. In Proc. of ICASSP, pp. 5470-5474, 2016.
Bibtex
@inproceedings{serizel2016group,
title={Group nonnegative matrix factorisation with speaker and session variability compensation for speaker identification},
author={Serizel, Romain and Essid, Slim and Richard, Ga{“e}l},
booktitle={2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={5470–5474},
year={2016},
organization={IEEE} }
References¶
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|